Computer Organization Note (Part 3 of 4)
Chapter 4-1 Processor: Single Cycle Ver
Introduction
基本的思路是,在之前我们学习了 C -> Assembly Language -> Machine Code 的过程。而 CPU 的工作就是执行机器码。例如,对于指令 add x10, x11, x12,我们要用 CPU 完成以下工作:
-
读取
x11和x12 -
计算两者的和
-
把和写到
x10中
在本门课程中,我们主要关心以下指令:
| Inst Type | Inst |
|---|---|
| R-Type | Arithmetic (add, sub, and, …) |
| I-Type | Load Register (ld) |
| S-Type | Store Register (sd) |
| SB-Type | Branch Jump (beq) |
| UJ-Type | Unconditional Jump (jal) |
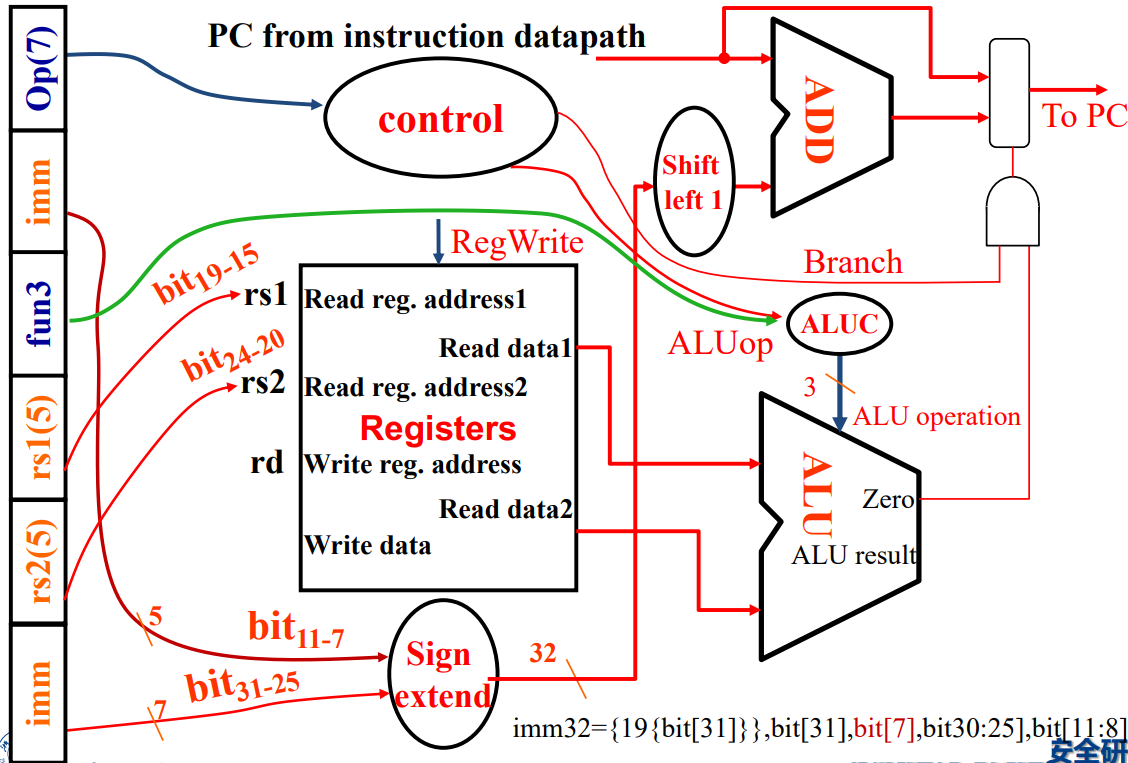
The Entire Processor
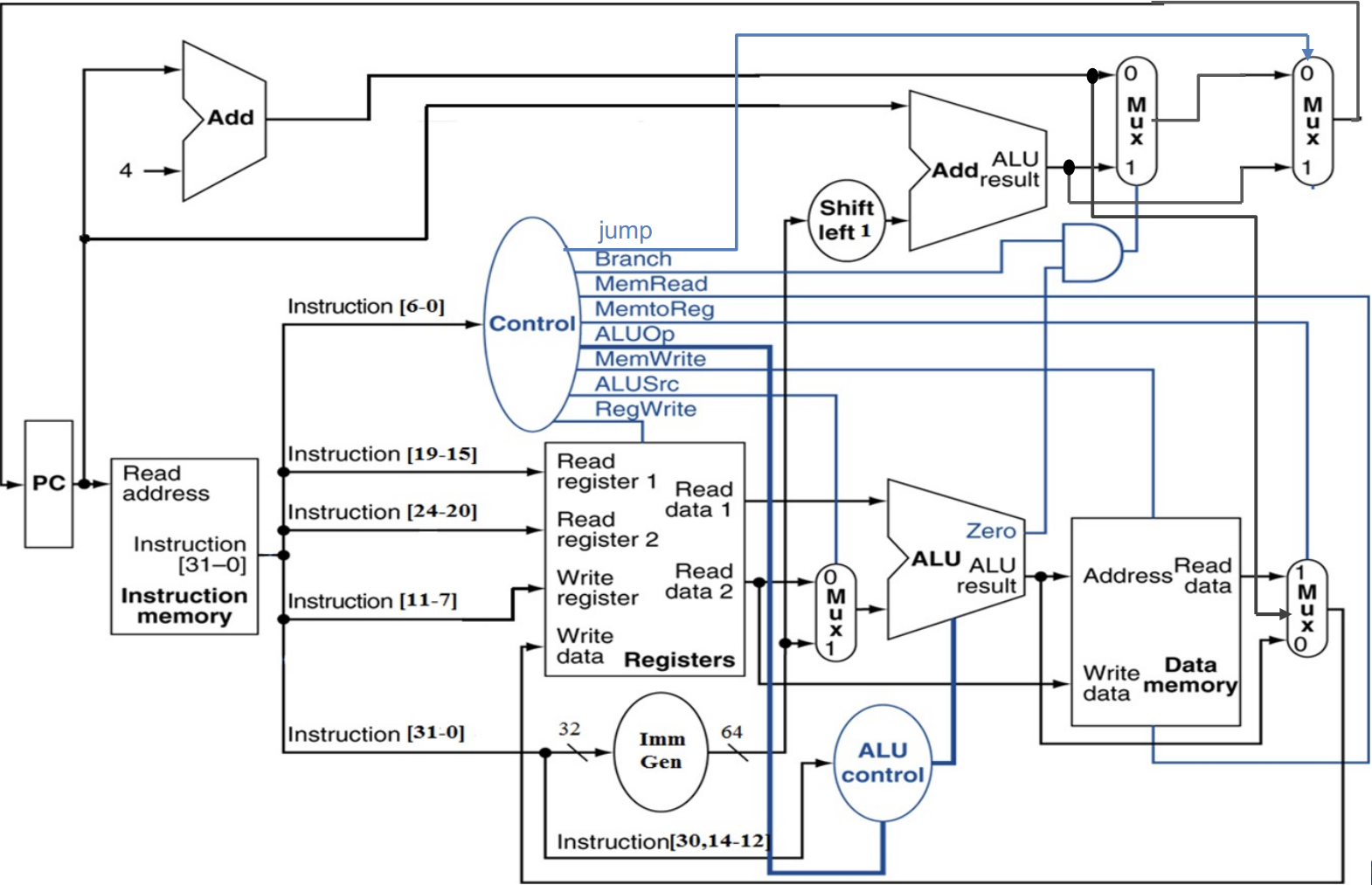
其实整个一节的关键信息就这一幅图。其中的一些关键点:
-
PC 表示当前的指令位置。
-
Instruction Memory 存放的是系列指令,可以理解为内存中的 Text 段。
-
Registers 寄存器。RISC-V 具有 32 个各 64 位的寄存器。
-
Data Memory 存放的是各种数据,可理解为内存中的 Data 段。
黑色的部分对应 CPU 的 Data Path,蓝色的部分对应 CPU 的 Control Unit。可以看到,Control 部分由 Opcode 全权完成。
接下来根据指令类型的不同,详细分析数据的走向。注意下面的图片仅作示意,不一定严谨。有的图片还有订正。
Processor Datapath Details
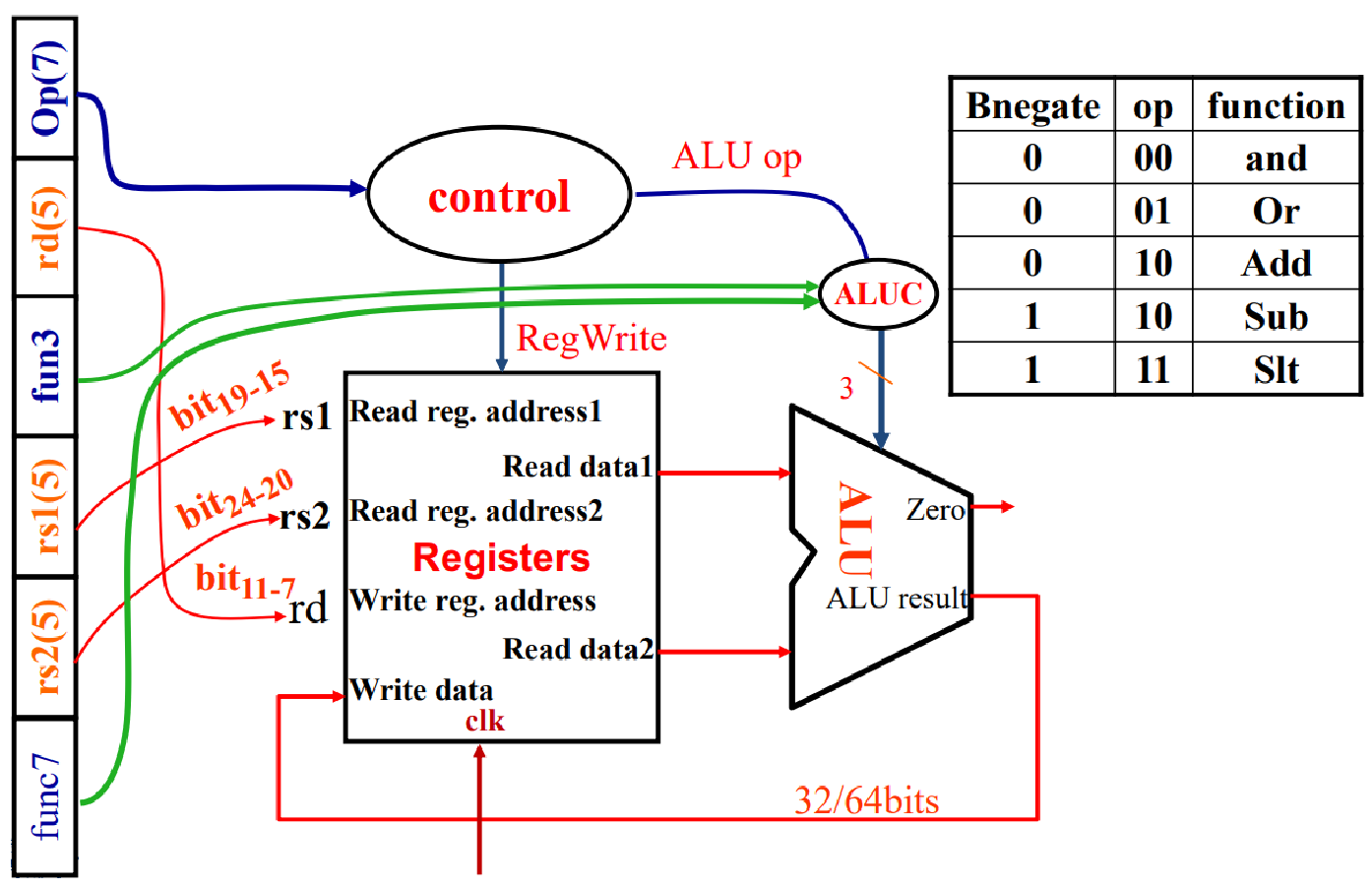
1. R-Type
2. I-Type (ONLY ld)
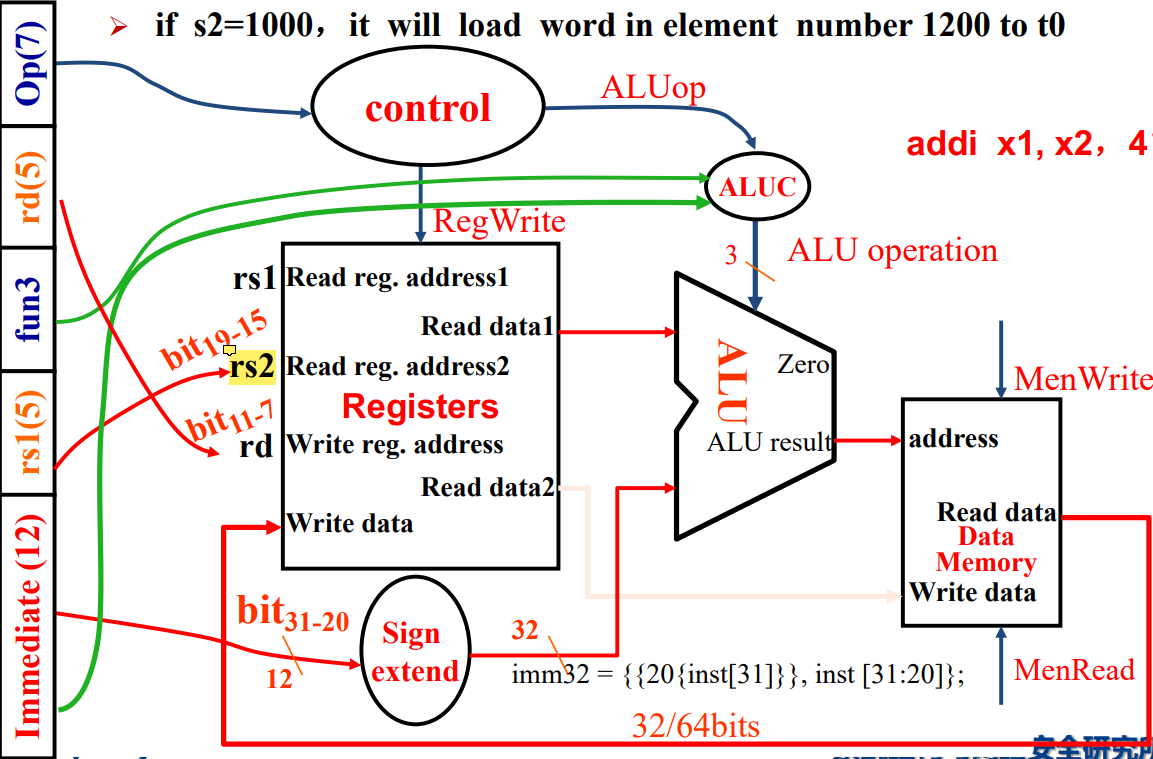
[ATTENTION] 图片有点问题,指令中的 rs1 连到寄存器的 rs2 上了,应当连到 rs1 上。
- 其中
20{inst[31]}是在做符号位拓展,因为本来也支持立即数为负的情况。
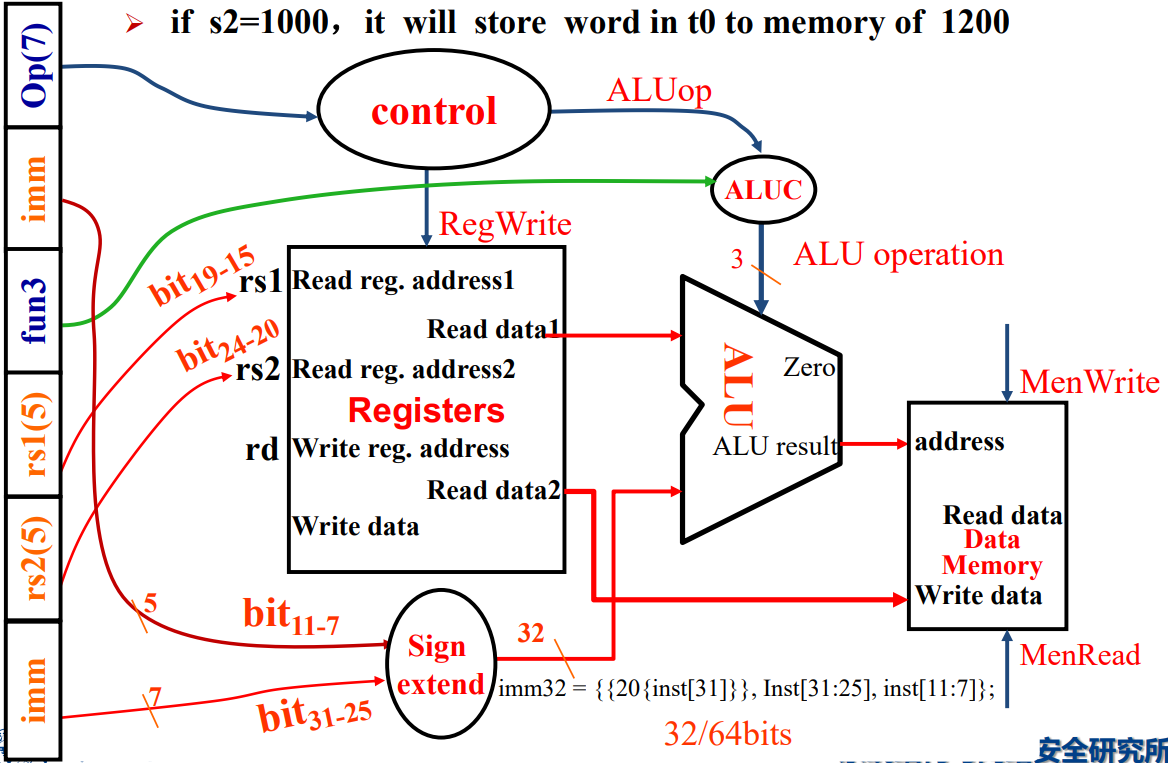
3. S-Type (ONLY sd)
4. SB-Type (ONLY beq)
- 这里 ALU 执行的是 sub 运算,然后根据
zero判断是否相等。如果zero为 1(beq 条件满足)且branch为 1(本条指令为 beq),那么就开跳。
5. UJ-Type (ONLY jal)
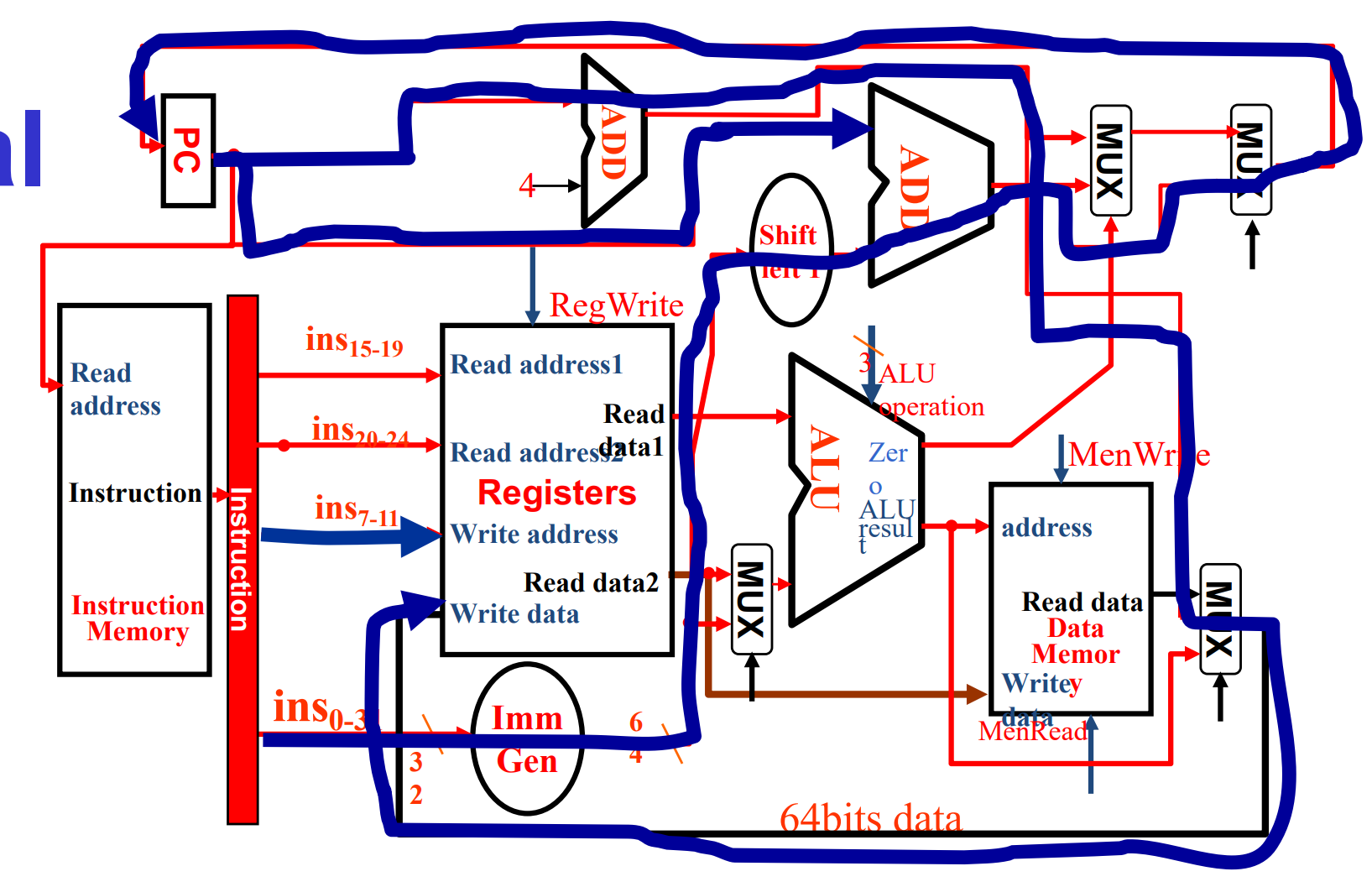
- 注意是 PC+4 进入到
Write Data中。
Controller
回顾一开始整个单周期 CPU 的图片,我们再贴一次:
根据 Opcode,我们需要通过 Controller 给出以下 8 个具体信号:
- R/W - RegWrite (0/1): 控制是否向寄存器里面写入。
- R/W - MemRead (0/1): 控制是否从内存读取。
- R/W - MemWrite (0/1): 控制是否向内存中写入数据。
- MUX - ALUSrc (0/1): 控制 ALU 下侧的数据来源,0 表示 rs2,1 表示 ImmGen。
- MUX - Branch (0/1): 表示当前指令是否为 branch jumping,用于控制下一个 PC。0 表示不为 branch,1 表示为 branch。结合 Zero 进行食用。
- MUX - Jump (0/1): 控制 PC 是否进行无条件跳转。例如当前指令为
jal时该值为 1。 - MUX - MemtoReg (2 bits): 控制返回到 write address 中的数据来源。分别表示 PC+4,内存读出数据,ALU 计算结果。
- ALU op (2 bits): 用于指导 ALU 进行的运算类型。后续会过一次 ALU Control。
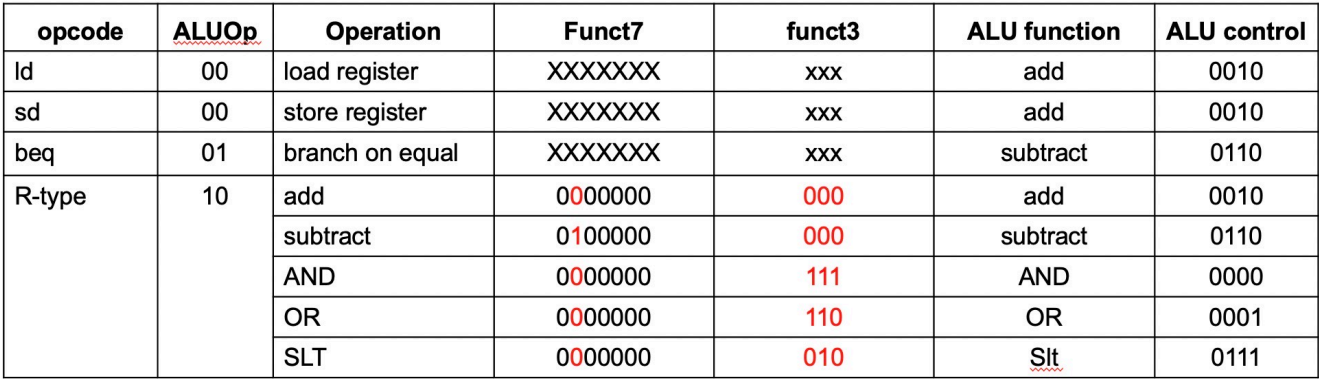
接下来专门讲一下 ALU 的具体控制。可以看到,ALU 的控制可以视为「两级」:
-
第一级:根据 ALU op 将不同类别的指令进行基础区分。
-
第二级:相同 ALU op 的基础上,再根据 funct3 和 funct7 对不同运算的指令进行区分(这部分 funct 从上图的
inst[30,14:12]线钻进去)。
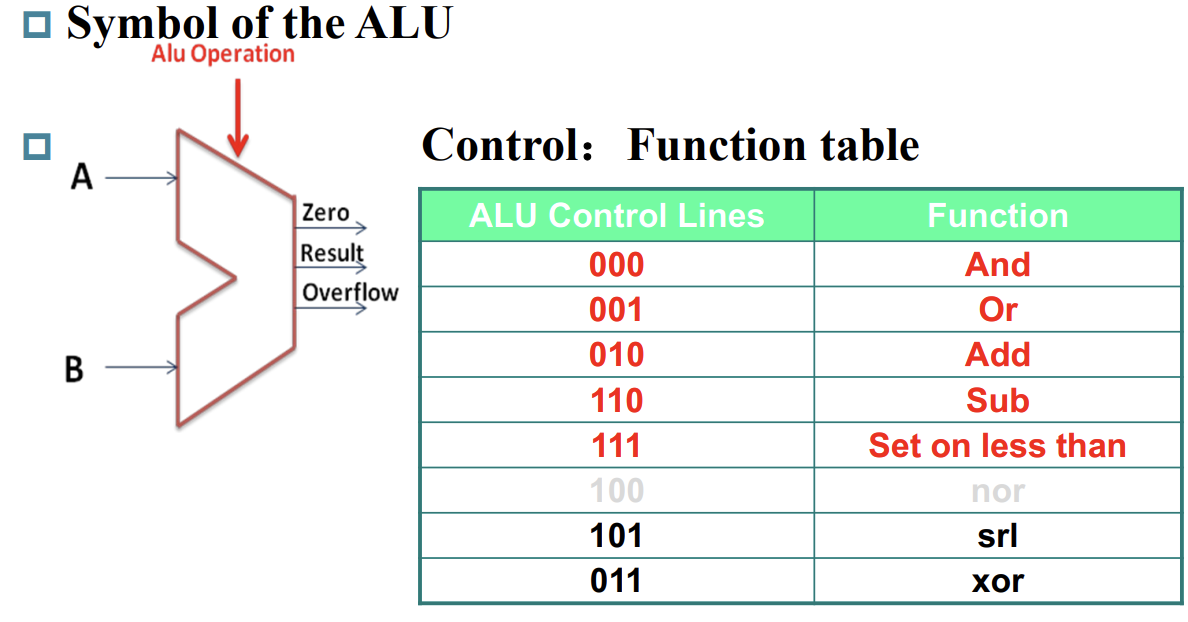
或许可以回顾一下 ALU:
Chapter 4-2 Processor: Pipeline Ver
Intro
-
不同指令耗时不一
例如在下图中,假设各部分的操作时长为:Memory Access, 200ps; ALU, 200ps; RegFile Access, 100ps。
那么执行一次
ld指令耗时为 800ps。执行一次sd指令耗时为 700ps。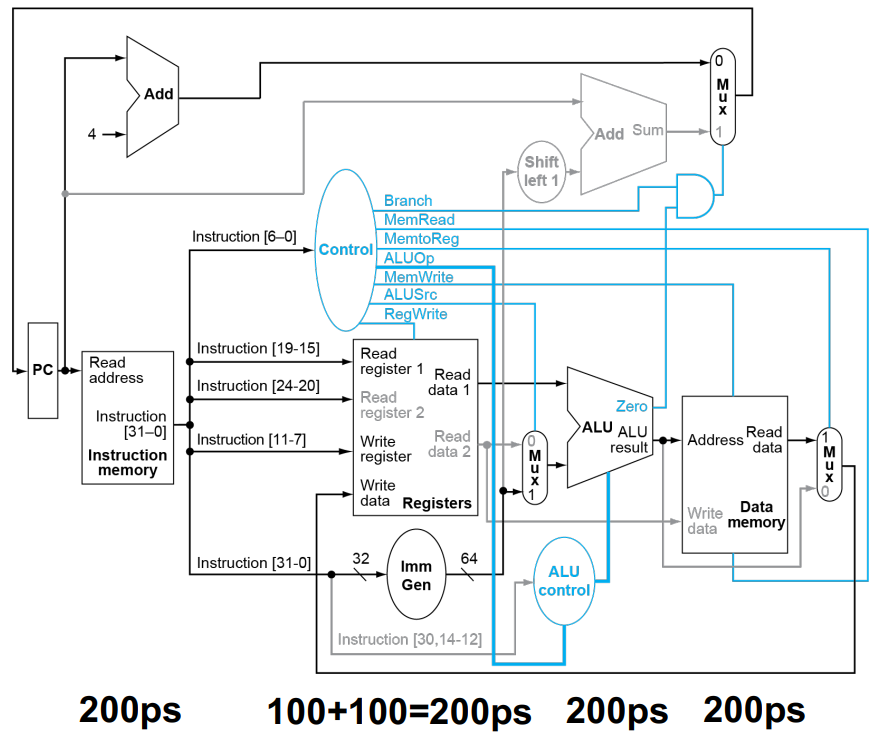
-
Pipelining Analogy
一种优化思路是从瓶颈(例如
ld)下手。然而我们还有另外一种优化思路——将【单周期 CPU】改为【流水线 CPU】。所谓流水线,可以参照这幅图: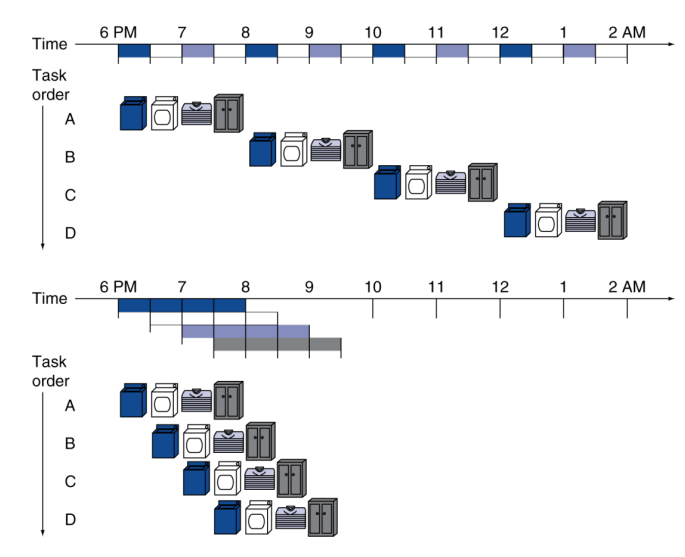
对应到 CPU 中,我们可以尝试把其分为若干个区域(或步骤),让每个区域同时工作,实现整体的流水线工作。
RISC-V Pipeline Intro
RISC-V CPU 可以划分为以下五个阶段:
- IF: Instruction fetch from memory
- ID: Instruction decode & read from register
- EX: Execute operation or calculate address (ALU Part)
- MEM: Access memory operand
- WB: Write result back to register
然后,一种简单的思路就是,我让五个阶段「流水线式」地工作,下图地两张图生动地说明了这一原理:

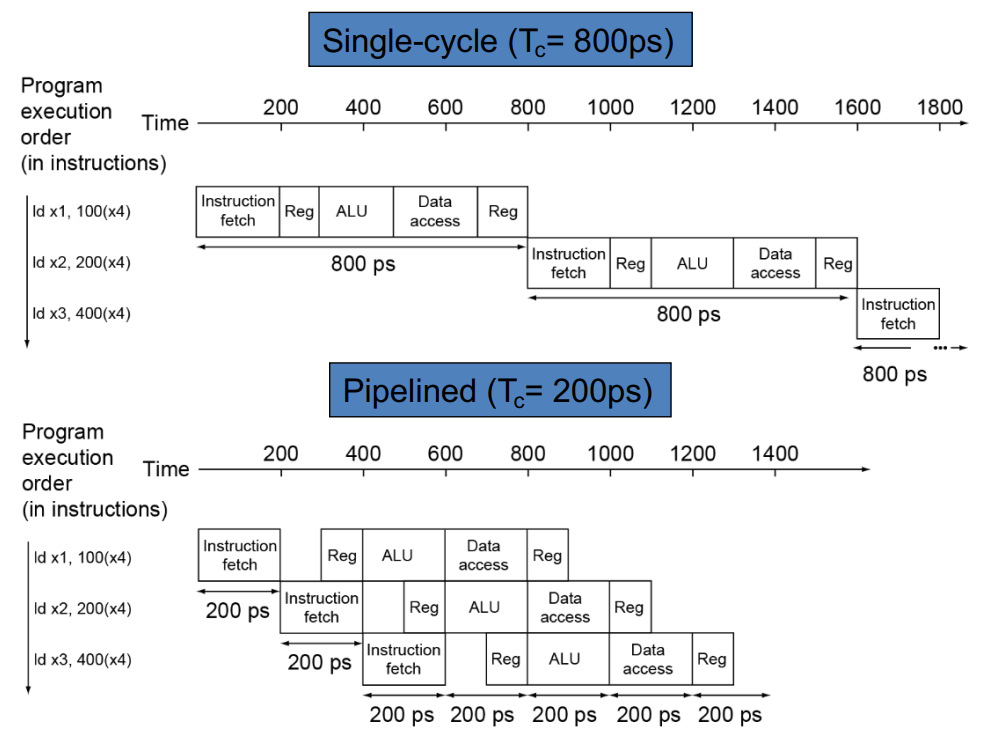
理想情况下,这一转变将让 CPU 提速 5 倍(因为有 5 个阶段,当然实际不会到达这个数值,看上图的下半部分可以理解;而且后面还有各种 hazards)。
Hazards
中文意为「冒险」,表示流水线 CPU 实现中可能遇到的各种容易出问题的情况。
1. Structure Hazard
可以想象,如果 data memory 和 instruction memory 是在同一部分的话,在 pipeline 的情形下,有的周期会调用同一块内存,这将产生冲突。
好在 RISC-V 的设计将 data memory 和 instruction memory 分隔开,所以我们几乎不用考虑 Structure Hazard。
2. Data Hazard
-
Problem: Data Hazard
有的时候执行某一个指令,要求前一个指令完成数据写入。考虑这样的两个相邻指令:
add x19, x0, x1 sub x2, x19, x3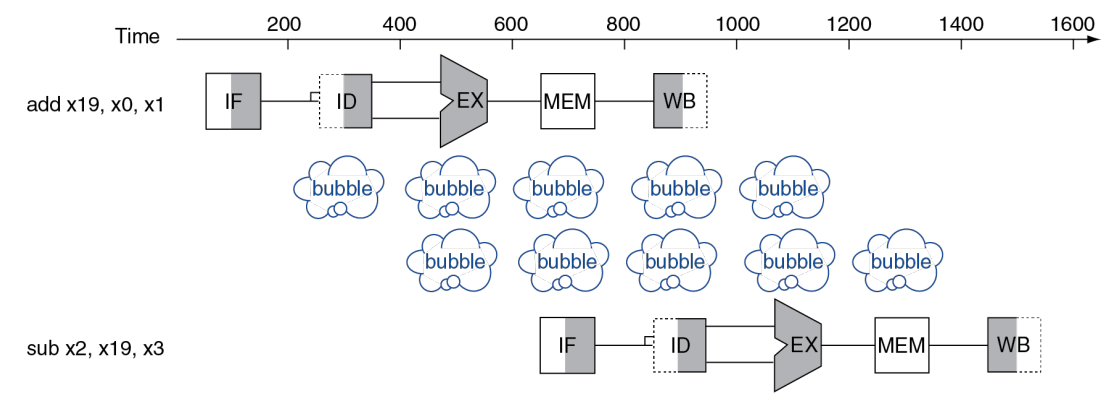
add 指令的 WB 必须要在 sub 指令的 ID 之前执行(原因显然),所以两个指令之间无法再「紧密地排列在流水线上」,中间需要隔两个 bubble。
【OBSERVATION】观察上上张图,WB 的写 reg 是在上半 cycle,ID 的读 reg 是在下半 cycle。这种设计的缘由其实在这里有所体现。
-
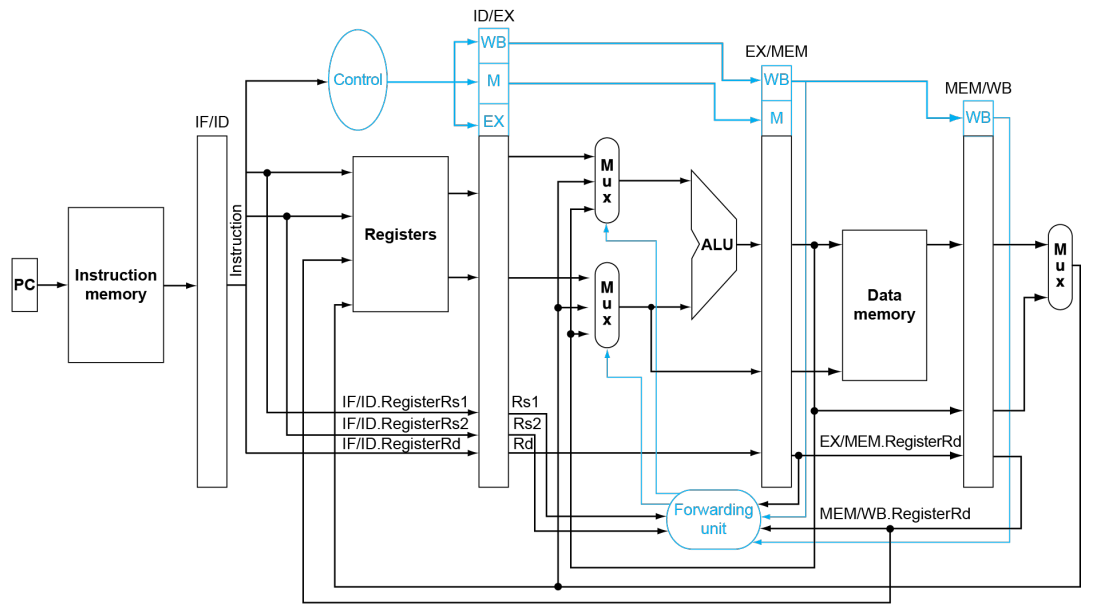
Solution: Forwarding
解决这种情况的一种方案是 Forwarding。大概思路是有的时候我们不必等待一个数据被写入 reg,然后才再次使用;而是可以直接用某种 extra connection 来直接高效地使用。下图演示了 Forwarding 的解决方案。
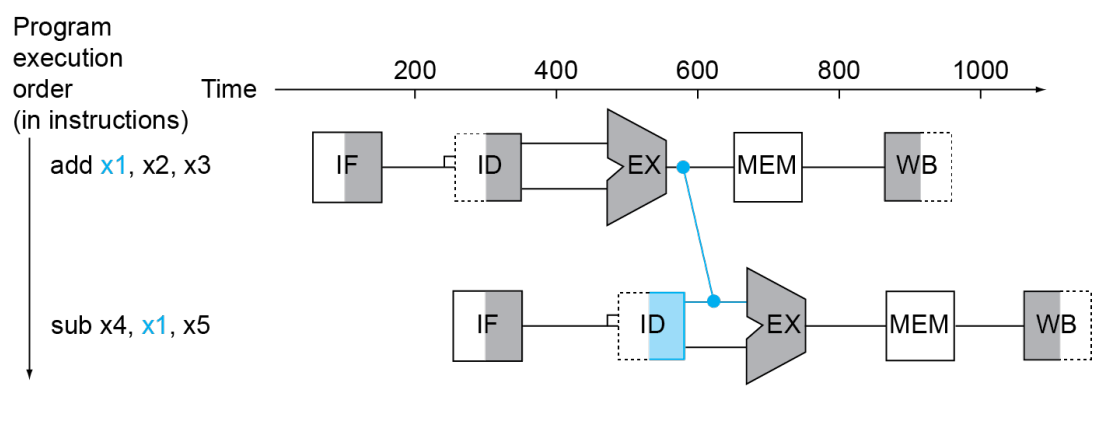
然而,并非所有 Data Hazard 都可以用 Forwarding 解决。考虑这样的情形:
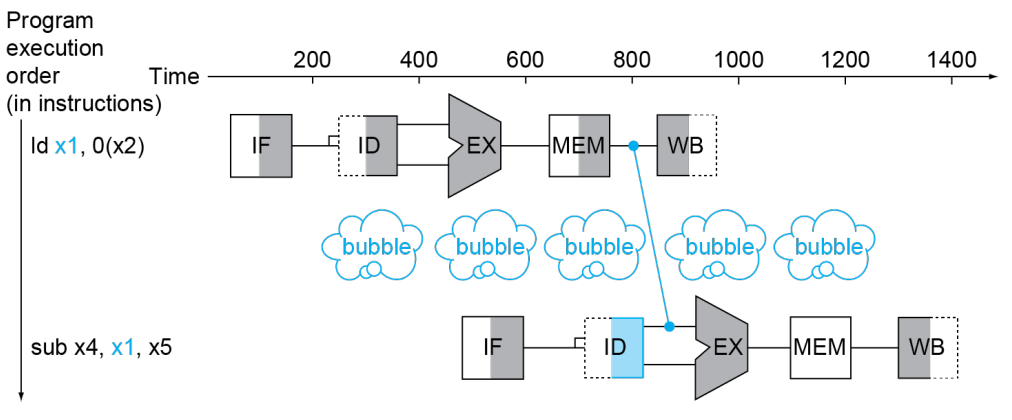
显然 sub 已经没办法再提前一个 cycle 了,不然 sub 的 EX 和 ld 的 MEM 将处在同一 cycle,而 sub 的 EX 需要 ld 的 MEM 提供前提数据。
不过,也可以通过修改汇编代码来规避这一问题——

3. Control Hazard
-
Problem: Stall on Branch
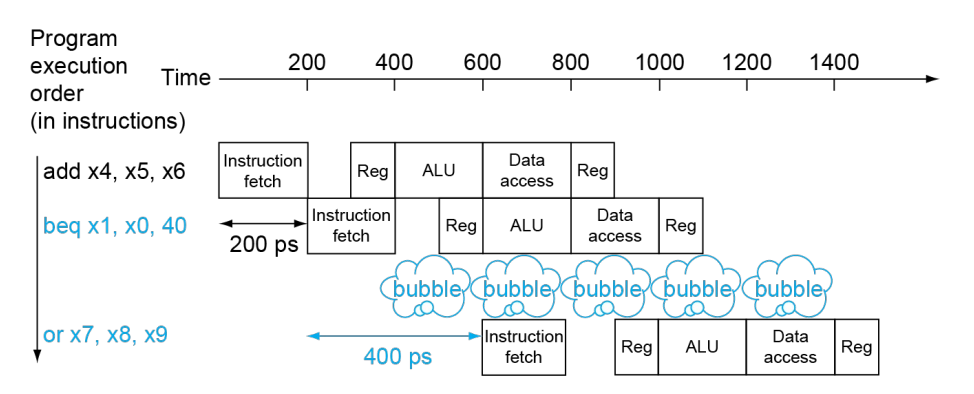
类似于这种 Branch Jumping 带来的停顿。上图有点问题,按理来说应当是两行 bubble。
-
Solution: Branch Prediction
字面意思,提前预测 branch 的结果。一般可以分为静态预测 (Static branch prediction) 和动态预测 (Dynamic branch prediction)。
静态预测一般是在软件层面上,根据普遍的 branch 选择结果进行预测。
动态预测一般是在硬件层面上,比如可以基于上一次 branch 的选择结果进行预测(考虑循环的情形,这种预测应当是成功率较高的)。
RISC-V Pipelined Datapath
在解决这一系列 hazards 之前,我们需要对 CPU 的结构进行修改。总的图形如下:
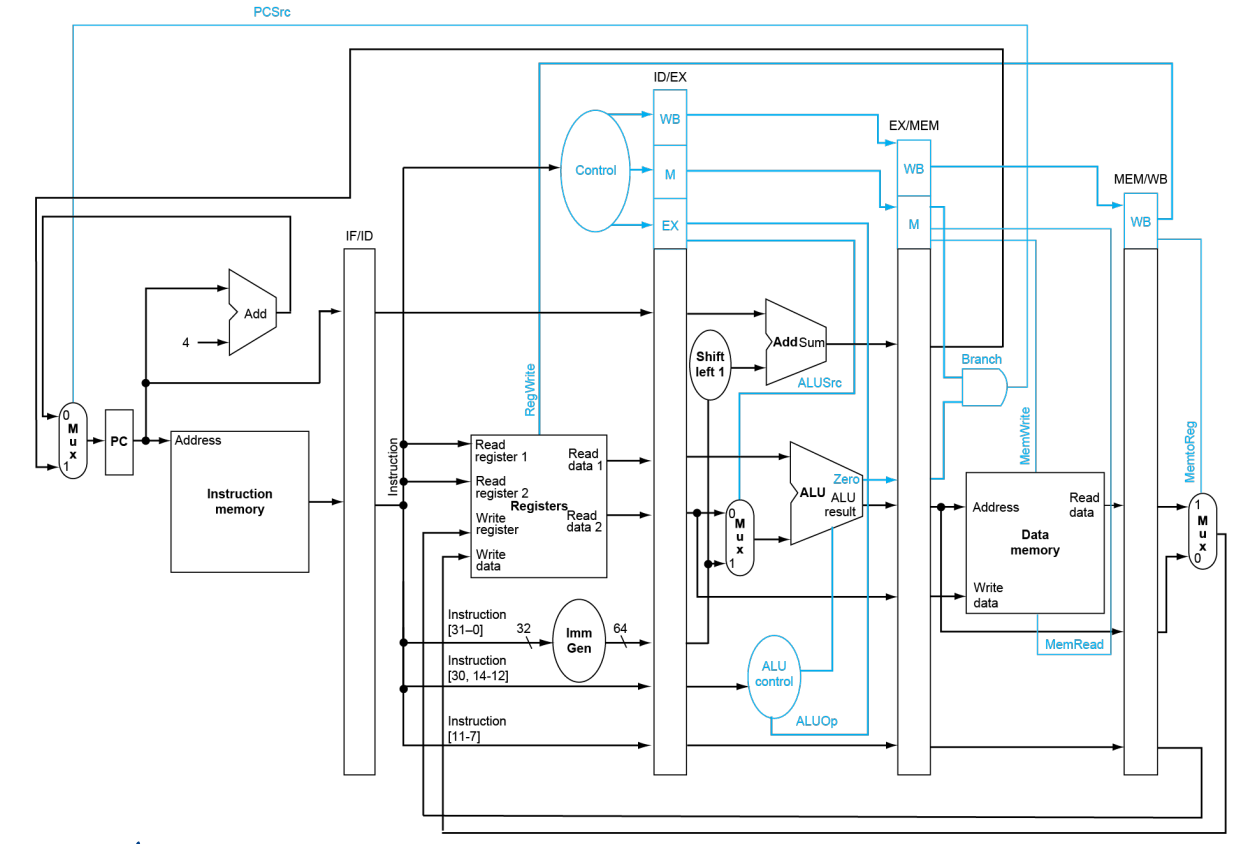
-
四个中间寄存器:
IF/ID,ID/EX,EX/MEM以及MEM/WB。字面意思表明了其所处位置。引入寄存器的目的是显而易见的,是为了使得在流水线上,每个周期的指令依然能正确读取数据。比如观察 Reg 的 Write Data 输入,肯定得引入
MEM/WB的值,而不是当前 Instruction Memory 的值。它们之间差了有 3 个 CC。注意这个改变只是最基本的,保证 pipeline 能正常运作的。它还没有解决 hazards 的问题。
-
Control 信号:
EX,MEM(M)以及WB。回顾单周期 CPU,除去
jal使用的 jump 信号,Controller 一共给出 7 个信号。根据其作用阶段的不同,将其分为-
EX (作用于 EX 阶段):包含
ALUop,ALUsrc。 -
MEM (作用于 MEM 阶段):包含
Branch,MemRead,MemWrite。 -
WB (作用于 WB 阶段):包含
MemToReg,RegWrite。
可以看到,在流水线上 Controller 对应的寄存器的大小是越来越小的,这一点也很好理解,毕竟到后面的 stage 某些 control signal 就不再起作用了。
-
Data Hazard Solution
1. R-R Case
情景:考虑以下的 RISC-V 指令:
sub x2, x1, x3
and x12, x2, x5
or x13, x6, x2
add x14, x2, x2
sd x15, 100(x2)
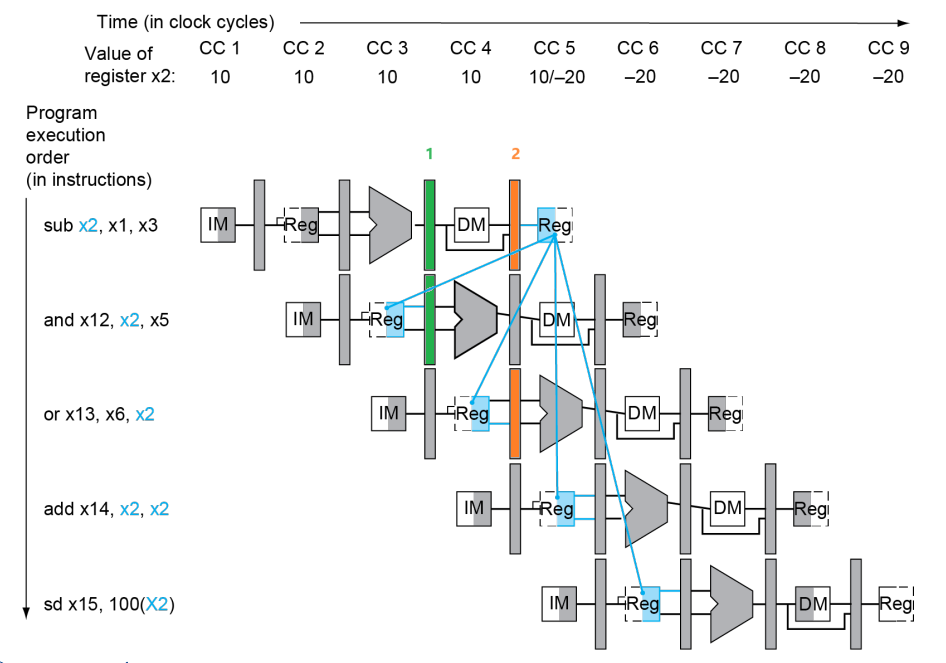
从上图可以看出,Data Hazard 发生当且仅当
-
前序指令的
rd和后序指令的rs1/rs2重合,即1a.
EX/MEM.RegisterRd=ID/EX.RegisterRs11b.
EX/MEM.RegisterRd=ID/EX.RegisterRs22a.
MEM/WB.RegisterRd=ID/EX.RegisterRs12b.
MEM/WB.RegisterRd=ID/EX.RegisterRs2四条中有一条满足即可。
-
执行写入操作
EX/MEM.Controller.RegWrite$= 1$MEM/WB.Controller.RegWrite$= 1$要求哪条满足主要是看上面选的是 1 还是 2。
-
不是虚空写入
EX/MEM.RegisterRd$\neq 0$MEM/WB.RegisterRd$\neq 0$要求哪条满足主要是看上面选的是 1 还是 2。
所以,我们可以加入这样的逻辑来完成 Forwarding:
2. Load-R Case
情景:考虑以下的 RISC-V 指令:
ld x2, 20(x1)
and x4, x2, x5
or x8, x2, x6
add x9, x4, x2
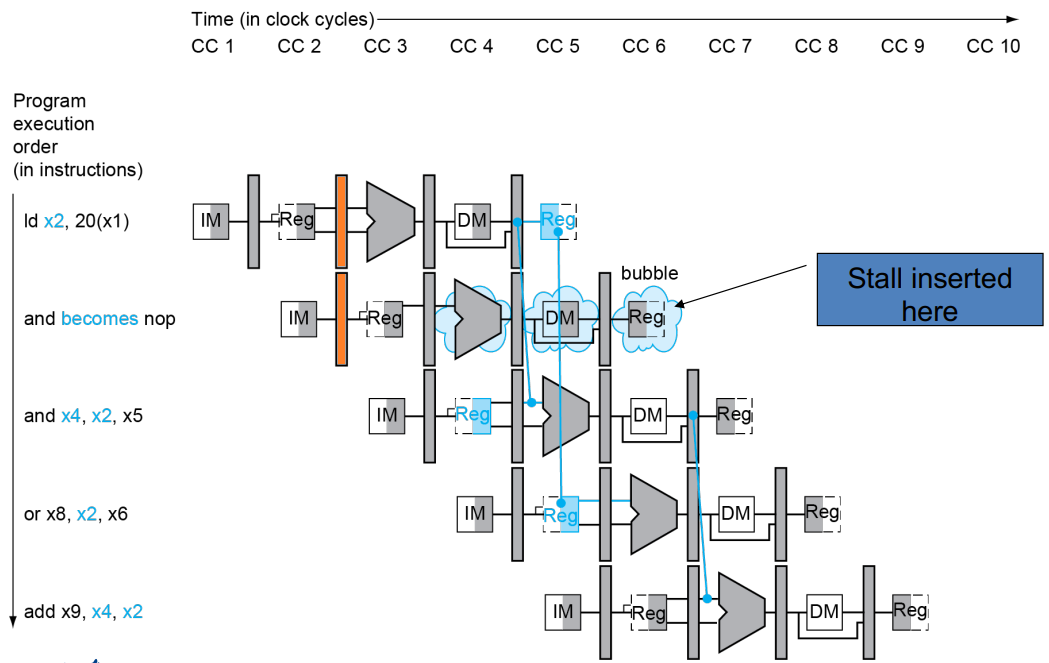
可以发现,第二行的指令无论如何都没有机会执行了,所以 add x4, x2, x5 必然会推后一个 CC。对于这一情况的判断,我们可以在上图橙色处完成。判断条件为
-
前序指令的
rd和后序指令的rs1/rs2重合,即a.
ID/EX.RegisterRd = IF/ID.RegisterRs1b.
ID/EX.RegisterRd = IF/ID.RegisterRs2两条中有一条满足即可。注意上面条件的两侧不要搞反。
-
执行 Load 操作
ID/EX.Controller.MemRead$= 1$
如果条件满足,我们首先要进行 Stall(熄火)。操作为
-
将当前指令(也就是下一个 CC 的 ID/EX)寄存器全部归零。
-
再次读取 PC,即不调到 PC+4。
Stall 后,我们再执行 Forwarding 来保证指令的正常运行。这一部分的 Forwarding 操作和 R-R Case 几乎一致,唯一的区别是 Forwarding 的执行是在判断生效的两个 CC 后。
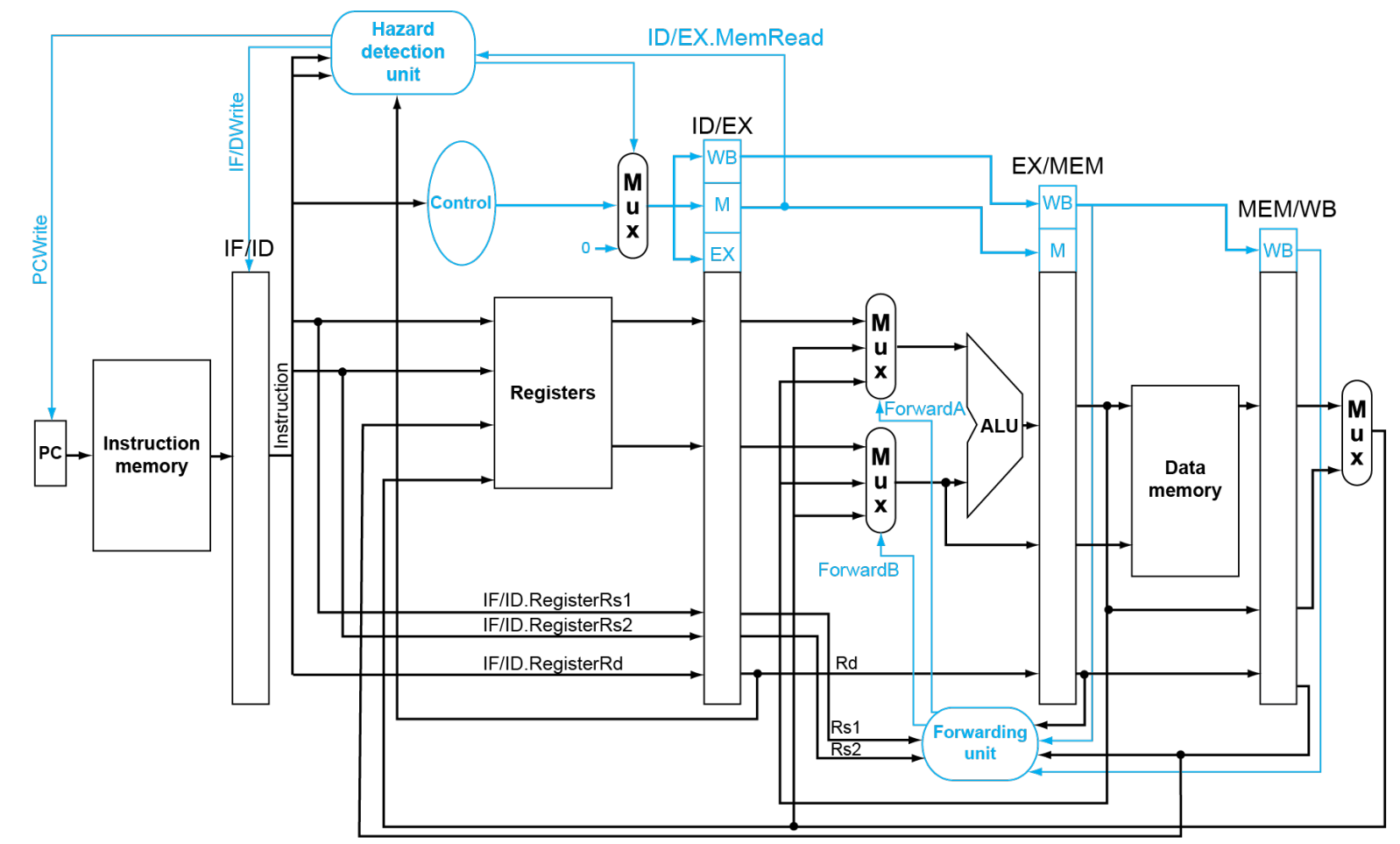
下图展示了考虑 Load-R Case 的 Pipeline。可以看到主要区别是加入了 Stall 的考量。
Branch Hazard Solution
1. Static Prediction
考虑以下指令:
36: sub x10, x4, x8
40: beq x1, x3, 32 // PC-relative branch to 40+32=72
44: and x12, x2, x5
48: orr x13, x2, x6
52: add x14, x4, x2
56: sub x15, x6, x7
...
72: ld x4, 50(x7)
我们假设采取静态预测(预测为 Not Taken),那么有
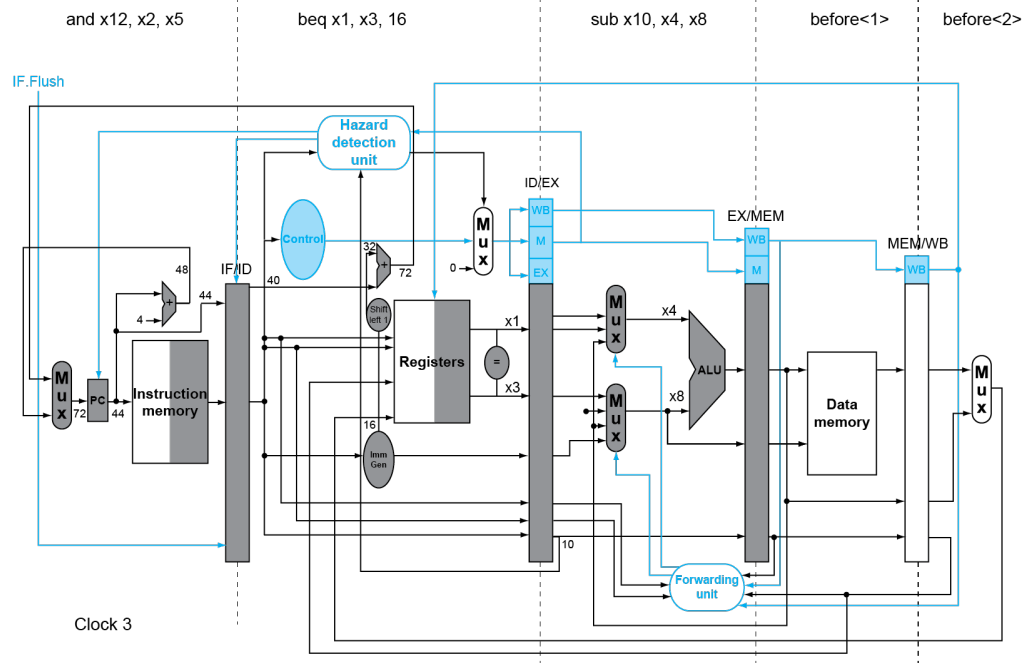
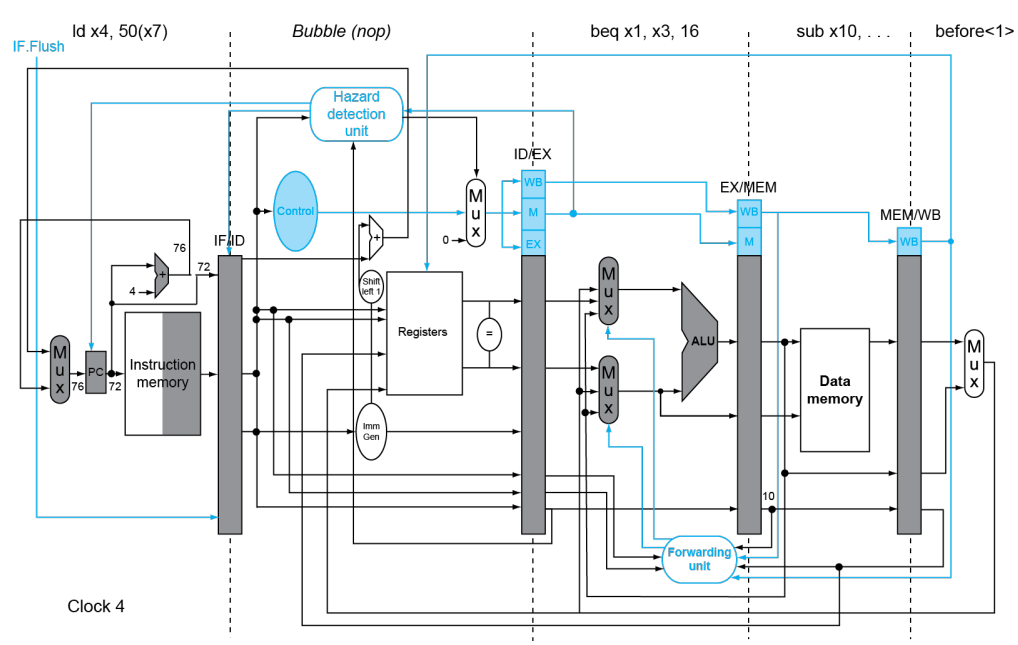
判断预测是否正确是看 x1 和 x3 是否相等。如果预测正确(的确为 Not Taken),则无事发生,所有指令照常进入流水线;如果预测错误(实际为 Taken),则需要
-
立刻对 IF/ID 寄存器进行 Flush,使得其下一个周期为 Bubble
-
向 PC 中输入 PC+Offset,使 IF 获取跳转后的指令
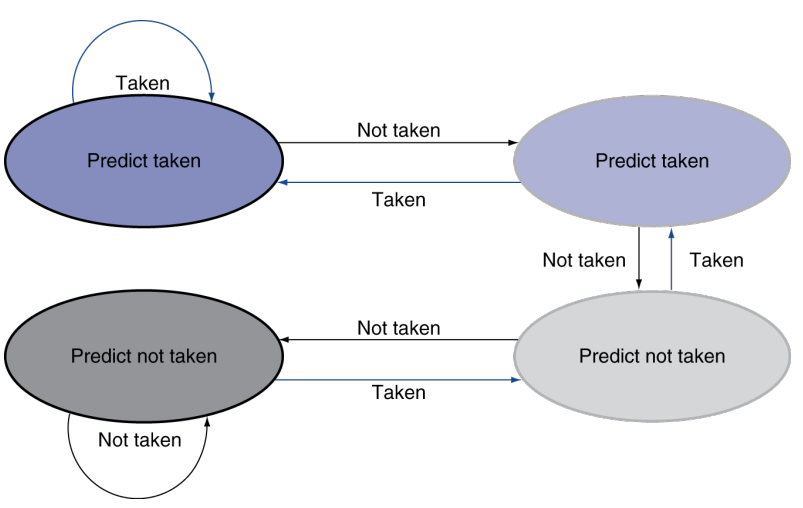
2. Dynamic Prediction
基本思路是,根据之前 branch 的选择结果决定之后的选择结果。这样做的依据是,假设我们处于一个循环体之中,大多数时候我们需要 take branch,只有循环开始 / 结束的时候才是 not take branch。
-
1-bit predictor
拿一个一位的寄存器存储上一次的 branch 结果。下一次 predict 根据这个 1-bit predictor 做出预测。
-
2-bit predictor
只会在连续两次的错误预测之后才会更改预测。从直观上看这个 predictor 更为「固执」。
3. Calculating the Branch Target
很明显,计算要跳到哪里 (Branch Target) 需要使用 ALU 进行计算,这会导致一定的延迟。
Branch Target Buffer 可以直接缓存下跳转的地址,下次就可以直接跳转并获取对应的指令。
Exceptions and Interrupts
-
可能导致异常与中断的情况
异常:例如未定义的 opcode, syscall 等。
中断:例如外界 I/O 进行了操作导致指令中断。
-
基本处理方法
- SEPC: 可以理解为存储出问题的 PC 的一个寄存器。
- SCAUSE: 可以理解为存储问题信息的一个寄存器。例如,SCAUSE 可以存储 opcode / hardware malfunction 等。
- handler: 可以理解为用于处理问题的专门指令。假设其地址位于
0000 0000 1C09 0000。
出问题时,先将 PC 存储到 SEPC 中,然后跳到专门的 handler。
handler 决定该采取何种措施。如果程序可重启,则采取适当措施后通过 SEPC 跳回去;反之则需要终止程序,根据 SEPC 和 SCAUSE 等信息报错。
-
Pipeline with Exceptions
可以看到,相比于处理 hazards 的 pipeline,这玩意儿主要是多了几个后面的指令寄存器的 flush。
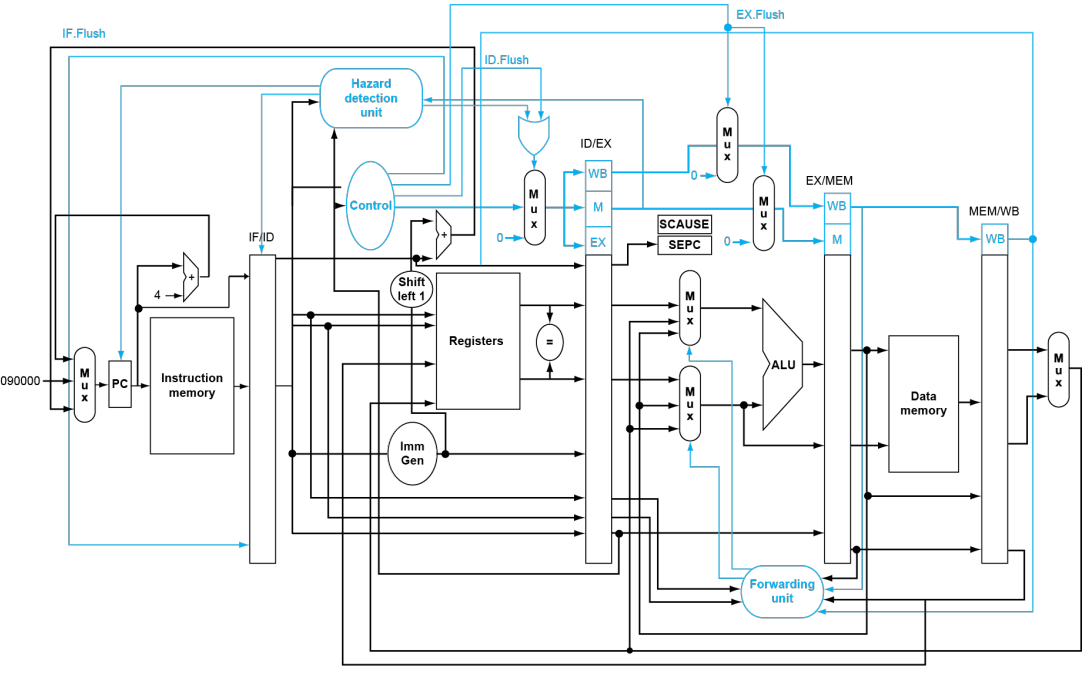
具体地,例如
add x1, x2, x1在 ALU 阶段发生异常,我们会执行以下步骤:- 保护
x1不被异常地写入。 - 完成
add x1, x2, x1之前的指令。 - flush 掉
add及之前的所有正在处理的指令(寄存器置零)。 - 设置好 SEPC 和 SCAUSE。
- 跳转到 handler。
- 保护
-
Multiple Exceptions
多重异常的情况,一般是处理最先出现的异常。
Instruction-Level Parallelism (ILP)
之前提到的 CPU 加速的方法是流水线,此外还有一种可能是:指令并行 (ILP)。
可以预见,这是一种非常冒险的举动,但它的确可以为 CPU 再提一下速度。
1. Introduction and Terms
-
Multiple Issue (多发)
可分为 static multiple issue 和 dynamic multiple issue。
Static Multiple Issue: 编译器来决定把哪些指令「捆在一起」,以规避可能发生的 hazards。
Dynamic Multiple Issue: CPU 来检测指令流并决定把那些指令「捆在一起」,编译器只起到辅助作用。显然这个难度更大。
-
Speculation (前瞻执行)
某些指令可以更早地执行(例如,提前预测并执行 branch outcome 处的指令)。当然,如果 speculation 是错误的,则需要 rollback。
前瞻执行可以由编译器完成,亦可以由硬件完成。
可以结合接下来的 RISC-V 静态双指令并行的例子理解 speculation。
2. Static Multiple Issue
显然,静态多发要求各个 issue slot 之内的指令互不依赖。当然,issue slot 之间的指令是可能产生依赖的。必要时,编译器可能向某个 issue slot 中加入 bubble。
-
RISC-V 静态双指令并行
基本思路:一个 issue slot 装两个指令,其中一个只能为 ALU/branch,另外一个只能是 load/store。例如:
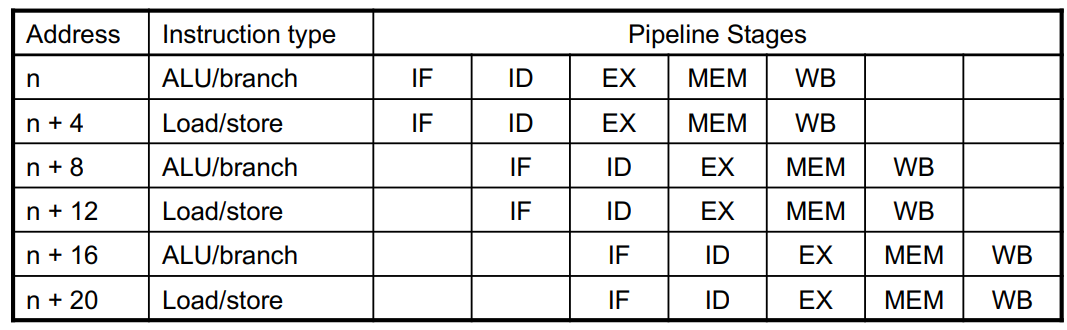
考虑双指令并行的流水线 CPU 如下图所示:
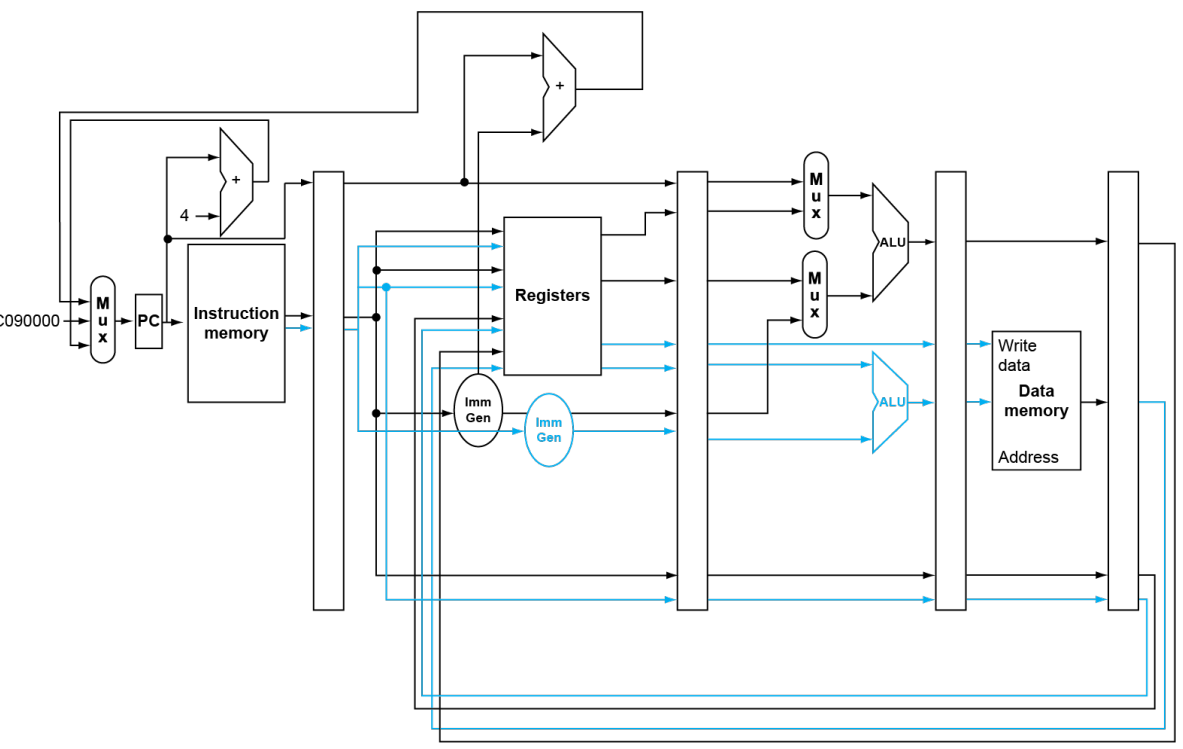
例如,我们可以看到 ALU 多了一个,并且多出来的那个不再接 MUX。这是因为 ld/sd 用的 ALU,其 ALUSource 已经固定。
当然,「打包」不能乱打。例如以下两条指令显然是不能位于同一个 issue slot 的:
add x10, x0, x1 ld x2, 0(x10)一个打包的正确示例如下:

注意:
-
ld x31, 0(x20)和add x31, x31, x21中间还隔了一个 CC,这是因为 load-use hazard 中间必须要空一个 CC。 -
sd x31, 0(x20)变为sd x31, 8(x20),这是因为我们把addi移到了sd之前。所以后做sd的话就需要做一些调整。 -
add x31, x31, x21和sd x31, 8(x20)之间的 data hazard 处理方法和之前讲的 R-R 基本一致,也是可以用 forwarding 无缝链接的。
-
-
循环展开
编译器层面 / 高级语言层面对循环进行展开,有利于指令并行加速。
这个例子执行了对相邻内存中的数据增加一个固定值
x21。使用循环展开来使得 ALU/branch 和 load/store 能更好地耦合。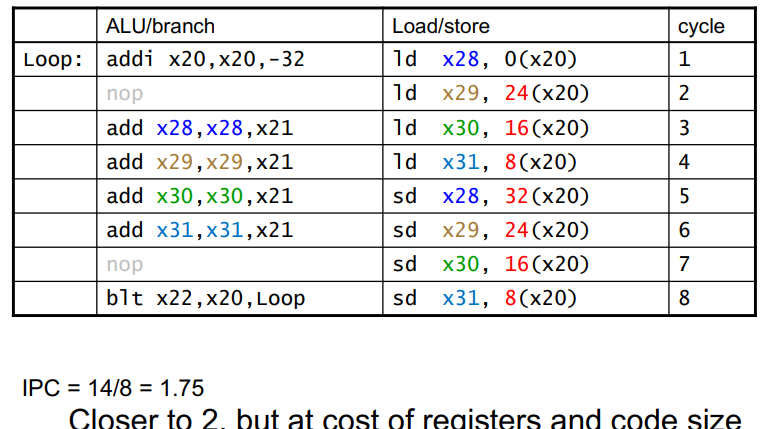
3. Dynamic Multiple Issue
-
动态调整指令的顺序
为了实现动态多发,不仅是要动态地把指令归到若干个 slots 中,必要时还可以动态调整指令的执行顺序。例如
ld x31, 20(x21) add x1, x31, x2 sub x23, x23, x3 andi x5, x23, 20可以把
add和sub对换,在不影响功能的基础上规避了一个 bubble。 -
动态多发基本框架
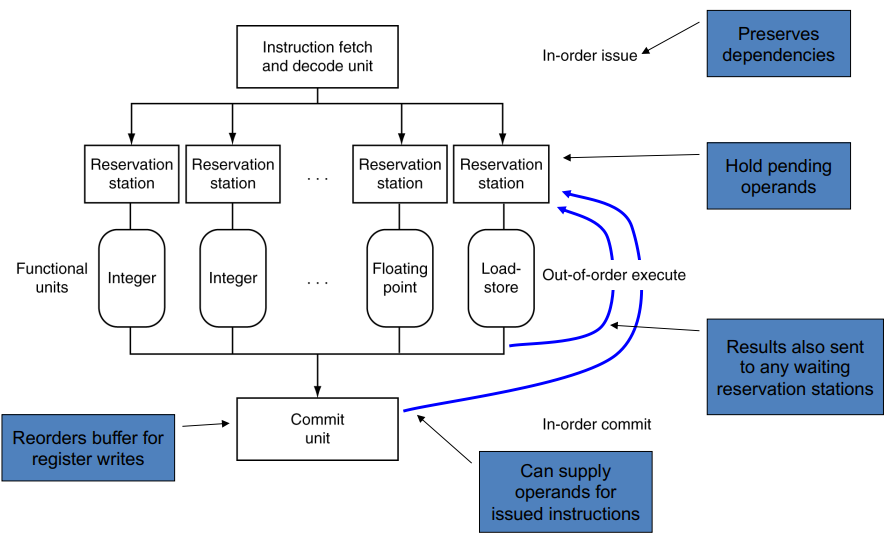
乱序执行,顺序 commit。
Enjoy Reading This Article?
Here are some more articles you might like to read next: